{kind=link}
{kind=link}
Chris Jenkins (Email)
INSTAAR, University of Colorado
19-Aug-2004
|
Relational Database Generator |
Contents
| Introduction How do the Foreign Keys relate to each other ? Data Resource Files rendered as RDB Error Trapping Importing into MS Access The second top line Error Trapping Data Mining Outputs as RDB |
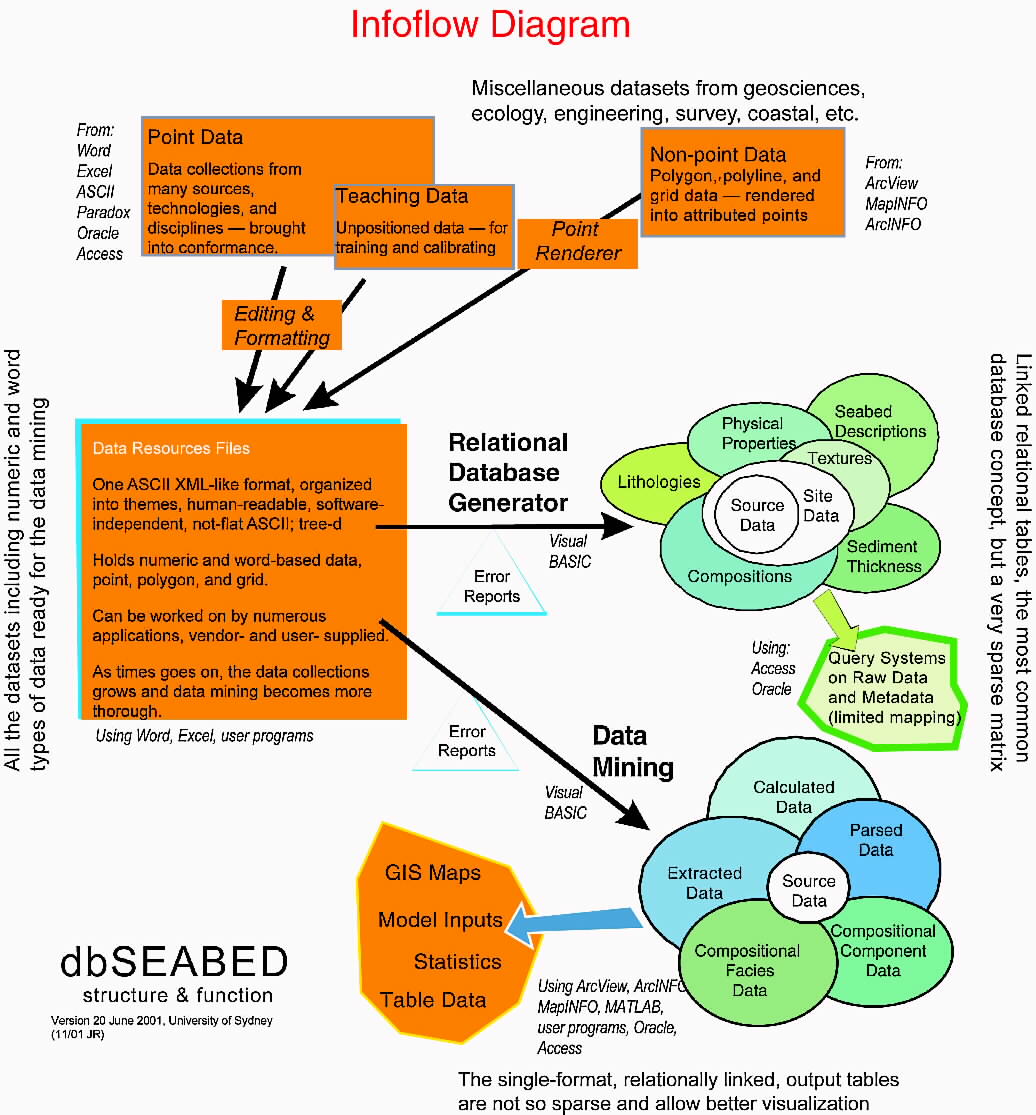
Across many academic and government agencies the Relational DataBase (RDB, 'RDBMS') model of data management is commonly used for seabed data systems. dbSEABED does have RDB outputs, but does not use that technology at its core. It is more efficient to import, maintain and process large amounts of seabed data in structured documents, and also there are many operations on the data which cannot be done (easily and inexpensively) under RDBMS - the linguistic parsing of sedimentologic data especially (verified in discussions with ORACLE representatives.)
dbSEABED generates RDB structures as output at 2 levels, in each case with a set of Foreign Keys which sequentially represent datasets, sites, samples, and items of metadata:
(i) of the sparse 'raw' data and metadata in the ASCII Data Resource Files (DRF) via the program 'db9_RDB*'Although the individual tables produced at each of these levels is 'flat ASCII', their combination in a RDB such as ACCESS creates a reasonably consolidated form of data in which only entries with a value will appear. The estimated density of data for the two levels of RDB (above) is: (i) 9% and (ii) 69% respectively.
(ii) of the geospatial files output by the program 'db9_MNE*'
The relationship of Data Mined, Relational Database output products to input data types is shown in the InfoFlow schematic.
Question: How do the Foreign Keys relate to
each other ?
The numeric relational keys for levels (i) and
(ii) do not match. Furthermore, because of edits from time to time
within
various Data Resource Files and adjustments to the working area, the
numeric
keys WITHIN levels (i) and (ii) can change from run to run.
The data resource files have an XML-like structure, that is, a tree rendition of parameters across a sparse matrix distribution of data.
The data at this first stage in dbSEABED is extremely sparse and very diverse, so is almost useless for the composition of maps, statistics, griddings and model inputs. But it is useful for querying the original data and associated metadata.
The program 'db9_RDB*' translates the Data Resource File format into RDB. It does this for a nominated working area defined by a Lat/Lon/WD/Subbottom_Depth box and a list of Data Resource Files to be included in the processing.
The outputs are into these relatable files:
| Information held | RDB file name | Data themes taken from the Data Resource Files |
| Data sources | *_srce.txt | SRC, SVY, MIF |
| Position and collection | *_site.txt | SFS, PYL, IMG |
| Lithological | *_lith.txt | LTH, COL, PET, AGE |
| Textural | *_texr.txt | TXR, TXG, GRZ |
| Physical Properties | *_phys.txt | ACU, GTC, MSL, PRB |
| Compositional | *_comp.txt | CMP, GCM, XRD, ENV, ISO |
| Seabed Descriptions | *_desc.txt | SFT, BIO, CLS, DIV |
| Oceanography | *_ocen.txt | OCE, TRB, DYN |
| Sediment Thicknesses | *_sedt.txt | SDT |
| Metadata and Error Notes | *_mdta.txt | All the above |
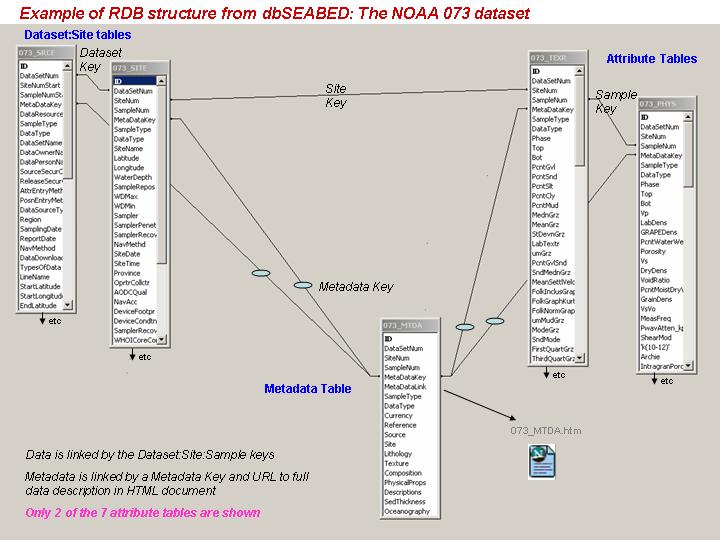
All the files of a run have the same numeric keys to dataset, site, sample and metadata entry, so that on import to ACCESS, ORACLE and other RDB, relationships can be set up readily.
There is also a HTML file generated ('*_mtda.htm') which holds all the data, metadata, and error reports from program 'db9_RDB' in one DRF type format. The relational metadata table holds URLs (either in MS Access or Oracle syntax) to specific lines in the formatted HTM file. Next to the DRF themselves, the formatted HTM file that holds the metadata, data and error reports all together is the best facility to use for tracking problems and queries in the data.
Error Trapping
A subsidiary role of 'db9_RDB' is as an error trap after data entry
of data into the Data Resource Files (DRF). It checks whether fields
have
the correct Number/Character data type and that numbers fall inside
plausibility
limits. For example % gravel must fall between 0 and 100.5% (0.5%
allows
for experimental errors).
The second-top line
Some databases take their cue on whether a column is string or numeric
from the type of the entry in the first data row (below column
headers).
MS Access appears to do this when external data is imported.
To force those applications to adopt the right type per column, the second-top line of each file is written with "XXXX" for string and "9999" for numeric. After importing the data into a Relational database, delete that record from the new database.
Importing into MS Access
Open MS Access with a blank database structure. Use
<File><GetExternalData><LinkFiles>
to import the tables, one by one. This is usually done from the
"Host/RDB"
folder. The files are "TextFiles" type.
The import settings are:
i. Delimited
ii. Comma delimited
iii. FirstRowContainsFieldNames and
iv. TextDelimiter = " (i.e., ASCII 34)
Once all are imported, relational links are established using the
<Tools><Relationships>
method. The table *_srce.txt is linked to *_site.txt using the field
"DataSetNum".
The metadata table is linked with the field "MetaDataNum". The
remainder
of the files - the attribute tables - are linked using the field
"SampleNum".
A typical setup is shown in this RDBschema.
The files output by the primary dbSEABED Data Mining program - 'db9_MNE*' - are individually flat ASCII files but are provided with numeric Foreign Keys for dataset, site and sample, so they can be linked in a relational structure. They consolidate the original data to ~70% and provides the best basis for the construction of maps, griddings, statistics and inputs to models.
![]()
Chris Jenkins (Email)
INSTAAR, University of Colorado
19-Aug-2004